
Pada saat artikel ini diterbitkan, pemungutan suara Pemilu 2019 sudah selesai sekitar 2 pekan lalu. Jumlah suara yang terkumpul di situs KPU pusat di laman https://pemilu2019.kpu.go.id/#/ppwp/hitung-suara/ baru di atas 50%. Akan tetapi, hasil hitung cepat (quick count) versi beberapa lembaga survei telah dipublikasikan lima jam sejak pemungutan suara dimulai (17 April 2019 pukul 07:00 WIB).
Publik begitu antusias dan bahkan memiliki berbagai pandangan akan hasil quick count yang ditayangkan. Ada yang gembira, ada yang sedih, ada yang langsung percaya, ada yang skeptis, dan ada pula yang biasa-biasa saja. Artikel kali ini akan membahas apa dan bagaimana suatu quick count dilakukan. Quick count merupakan suatu proses ilmiah, terutama didasarkan pada ilmu statistika, untuk mendapatkan hasil pemungutan suara secara cepat.
Quick count di Indonesia dimulai pada tahun 2004 oleh Lembaga Pelatihan, Penelitian, Penerangan, Ekonomi dan Sosial (LP3ES) bekerjasama dengan The National Democratic Institute for International Affairs (NDI) di Pemilu Legislatif 5 April 2004. Mereka mendapatkan selisih 0,9 persen dibandingkan hasil resmi KPU. Pada Pemilu Presiden Putaran I pada 5 Juli 2004, selisih perhitungan mereka membaik dengan selisih 0,5 persen. Setelah keberhasilan LP3ES-NDI memprediksi hasil pemilu dengan metode quick count, berbagai lembaga survei turut menggunakannya untuk Pemilu dan Pilkada.
Lembaga survei yang dapat memublikasikan hasil quick count diatur oleh Peraturan Komisi Pemilihan Umum (KPU) No. 23 Tahun 2013 tentang pelaksanaan survei dan penghitungan cepat hasil pemilihan umum. Pasal 22 menyatakan bahwa lembaga survei dan hitung cepat dinyatakan terdaftar apabila melakukan pendaftaran kepada KPU, KPU Provinsi dan KPU Kabupaten/Kota dengan menyerahkan persyaratan seperti surat pernyataan mengenai netralitas lembaga survei, benar-benar melakukan wawancara dalam pelaksanaan survei atau jajak pendapat, menggunakan metode penelitian ilmiah, dan melaporkan metodologi pencuplikan data.
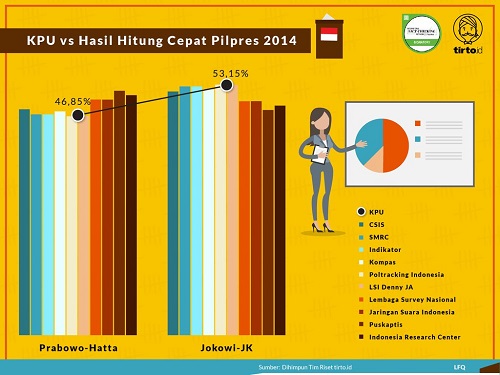
Untuk melihat seberapa akurat metode quick count, kita dapat melihat infografis yang dihimpun oleh tirto.id sejak pilkada DKI 2012. Kita dapat melihat bahwa lembaga-lembaga survei yang kredibel mampu menampilkan hasil quick count yang sesuai dengan hasil perhitungan riil (real count) KPU.
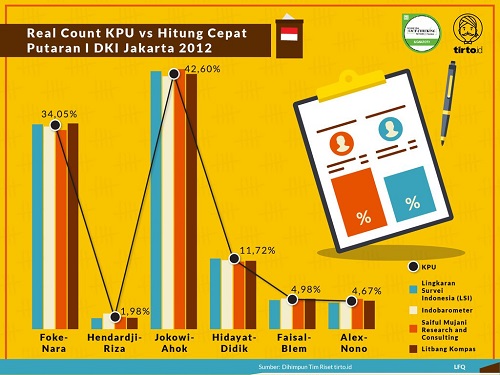
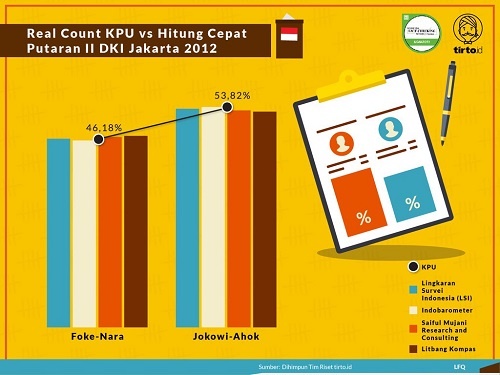
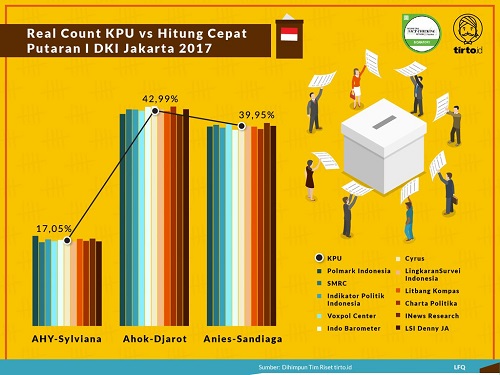
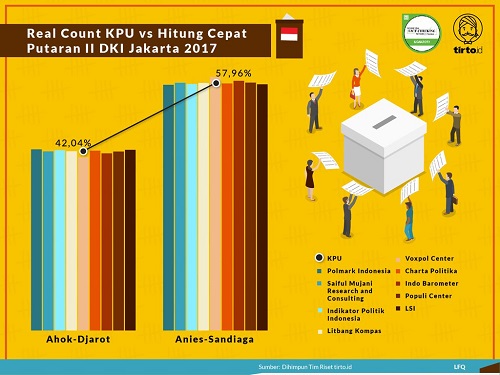
Sekarang, bagaimanakah sebenarnya quick count itu dilakukan? Tentu saja untuk mendapatkan data yang representatif kita perlu memiliki jumlah sampel yang cukup. Namun, apakah jumlah sampel yang makin besar menunjukkan hasil yang makin akurat? Ternyata tidak. Faktor lain yang perlu diperhatikan adalah bagaimana sebaran sampel tersebut, apakah mewakili sebaran data aslinya. Setiap provinsi di Indonesia memiliki kepribadian dan budaya yang khas sehingga sampel harus menyebar di seluruh provinsi. Penduduk desa dan perkotaan juga memiliki karakteristik yang berbeda. Maka, sebaran data harus dipikirkan untuk mengakomodasi rasio pedesaan dan perkotaan yang sesuai dengan Indonesia.
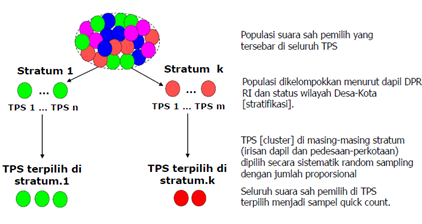
Saiful Mujani Research and Consulting (SMRC) menggunakan metode quick count stratified systematic cluster random sampling. Stratifikasi berarti sampel TPS dikelompokkan menurut wilayah dapil DPR dan status pedesaan-perkotaan. Pada setiap stratum, dipilih TPS secara random tetapi sistematis dengan jumlah proporsional yang totalnya 6000 TPS, seperti ditunjukkan pada ilustrasi.
Terdapat dua kuantitas yang penting di dalam suatu quick count, yaitu estimasi perolehan suara dan margin kesalahan (margin of error atau moe). Estimasi perolehan suara dapat dihitung dengan persamaan
\hat{p} = \displaystyle \frac{\sum_{h=1}^{H} \sum_{i=1}^{n_h} \frac{N_h}{n_h} y_{hi}}{\sum_{h=1}^{H} \sum_{i=1}^{n_h} \frac{N_h}{n_h} x_{hi}}
dengan Nh adalah total TPS di stratum h; nh adalah banyaknya TPS quick count di stratum h; yhi jumlah suara capres/partai di TPS i stratum h; xhi adalah jumlah suara sah di TPS i stratum h . Margin of error didapatkan dengan rumus
\mathrm{MOE} = 2 \times \displaystyle \sqrt{\frac{1}{\hat{X}} \sum_{h=1}^{H} \frac{N_h(N_h - n_h)}{n_h}\hat{v}ar_h} \times C
dengan estimasi total suara sah adalah
\hat{X} = \displaystyle \sum_{h=1}^{H} \sum_{i=1}^{n_h} \frac{N_h x_{hi}}{n_h}
dan varian data
\hat{v}ar_h = \displaystyle \sum_{i=1}^{n_h} \frac{(v_{hi} - \bar{v}_h)^2}{n_h - 1}, v_{hi} = y_{hi} - \hat{p}x_{hi} , \bar{v}_h = \displaystyle \sum_{i=1}^{n_h} \frac{v_{hi}}{n_h}
C pada rumus MOE merupakan konstanta potensi bias untuk daerah yang tidak terlingkupi dan biasanya bernilai mendekati 1. Nilai MOE biasanya ditetapkan maksimal 5% yang kemudian menjadi pedoman penentuan jumlah sampel dan sebaran.
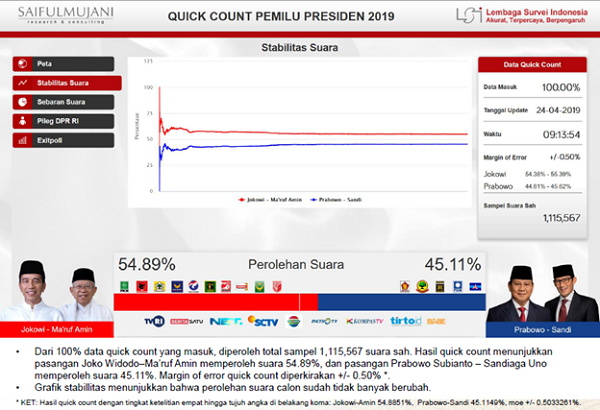
Dari jumlah data yang terkumpul, kita dapat melihat stabilitas suara dari quick count yang dilakukan SMRC seperti pada gambar. Tampak bahwa semakin banyak data yang masuk, suara semakin stabil.
Selain untuk quick count, ilmu statistika ini telah digunakan di berbagai hal dengan modal utama adalah data yang masif. Mulai dari masalah transportasi, memprediksi kemacetan di jam-jam tertentu hingga aplikasi sosmed yang mengetahui apa kegemaran kita, barang yang suka kita beli, dan ke mana kita bepergian. Jangan heran bila iklan-iklan yang muncul di sosmed bisa jadi sangat pas dengan yang kalian butuhkan karena perangkat cerdas mereka mempelajari data-data hasil browsing kalian.
Bahan bacaan:
- Artikel serupa tentang matematika dan pemilu di Majalah 1000guru:
http://majalah1000guru.net/2018/12/matematika-pemilu/ - https://norstatgroup.com/blog/articles/news/detail/News/what-sample-size-is-representative/
- http://www.saifulmujani.com/blog/2019/04/24/metodologi-proses-dan-hasil-quick-count-pemilu-2019
- https://tirto.id/rekam-jejak-quick-count-pilkada-hingga-pilpres-hasilnya-meleset-dmWt
Penulis:
Eddwi Hesky Hasdeo, peneliti fisika komputasi di Lembaga Ilmu Pengetahuan Indonesia.
Kontak: heskyzone(at)gmail.com


