
Teman-teman pasti sering mendengar istilah MP3, bukan? MP3 bisa ada di dalam HP, laptop, komputer, ataupun audio player-mu. Apa sebenarnya MP3? Bagaimana peran matematika dalam teknologi audio ini?
Representasi Suara
Sebelum memulai penjelasan mengenai MP3, ada sedikit pendahuluan tentang representasi audio di dunia digital, seperti komputer, HP, dan perangkat sejenisnya. Pada dasarnya, sinyal suara adalah gelombang yang mempunyai nilai simpangan sebagai fungsi waktu, dinotasikan dengan . Sinyal suara ini kemudian diteruskan ke sebuah sistem digital. Sistem digital seperti komputer hanya mengetahui nilai 0 dan 1. Untuk merepresentasikan sinyal suara di komputer kita melakukan sampling.
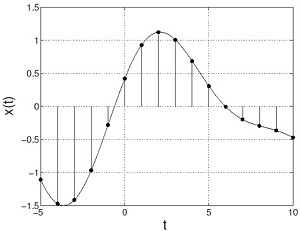
Sumber gambar: cnx.org
Data simpangan gelombang sebagai fungsi waktu x(t)ini kemudian ditransformasi menjadi simpangan gelombang sebagai fungsi frekuensi x(f). Cara untuk mentransformasi sinyal ini disebut transformasi Fourier. Penjelasan lebih lanjut tentang transformasi ini dapat dibaca pada rubrik matematika Majalah 1000guru edisi April 2014.
Sampling Frekuensi
Sampling frekuensi adalah pengambilan batas frekuensi untuk dapat merepresentasikan sinyal suara dengan optimal. Seperti yang kita pelajari sewaktu SD, batas pendengaran manusia adalah dari 20Hz sampai 20 kHz. Untuk merepresentasikan sinyal suara dengan akurasi sempurna, kita perlu melakukan sampling dengan frekuensi dua kali lipat dari ambang batas atas, yaitu 40 kHz, atau lebih.
Dengan alasan historis dan implementasi perangkat elektronik pada sistem pemrosesan audio modern, kita sering menggunakan frekuensi 44,1 kHz atau 48 kHz. Pada dasarnya, dari sisi persepsi manusia tidak ada perbedaan antara kedua sampling frekuensi tersebut, karena yang pertama bisa merekonstruksi sampai frekuensi 22,05 kHz dan yang satunya hingga 24 kHz.
Bit depth
- Selain sampling frekuensi, hal yang juga penting dari sistem digital adalah bit depth. Yang dimaksud dengan bit depth adalah tingkat ketelitian sampling yang merepresentasikan sinyal suara. Sesuai dengan teori gelombang, sinyal suara bisa memiliki range nilai antara -A sampai A, dengan A adalah amplitudo (simpangan maksimum) gelombang.
- Rentang nilai simpangan tersebut akan diubah ke dalam sinyal digital yang jumlah sampling-nya ditentukan oleh jumlah bit. Contohnya, kalau kita menggunakan 2 bit, kita bisa punya 4 alternatif nilai sampling, yaitu -0.75A, -0.25A, 0.25A dan 0.75A. Kalau kita menggunakan 4 bit, kita bisa mendapatkan ketelitian 2 kali lipat, dan seterusnya.
- Sistem audio modern menggunakan 16 atau 32 bit sehingga memiliki ketelitian sebesar 216 atau 232 untuk nilai sampling sinyal dengan rentang -A hingga A. Sistem audio premium bahkan ada yang menggunakan 64 bit untuk kualitas suara yang makin jernih.
- Dari dua penjelasan di atas mengenai sampling frekuensi dan bit depth, kita dapat sedikit gambaran mengenai ukuran file di komputer. Contohnya, tanpa teknik kompresi seperti MP3, file audio yang durasinya 3 menit dengan bit depth 16 bit dan sampling frekuensi 48 kHz akan menghasilkan ukuran file sebesar (3 x 60) detik x 16 bit x 48000 Hz = 138.240.000 bit. Jadi, pada sistem operasi Windows, ukuran file yang kita dapatkan adalah 131.8 MB. Cukup besar untuk sebuah lagu berdurasi 3 menit!
Pemanfaatan persepsi manusia
MP3 bekerja dengan memanfaatkan karakteristik pendengaran manusia. Dari hasil riset kedokteran dan psikologi, ada beberapa hal menarik pada telinga manusia yang bisa dimanfaatkan untuk mengurangi data yang perlu disimpan.
- Batas pendengaran manusia
Berdasarkan frekuensi gelombang suaranya, suara terkecil yang bisa didengar manusia berbeda-beda. MP3 memanfaatkan karakteristik ini untuk mengurangi data audio. Semua komponen sinyal suara yang ada di bawah batas pendengaran tidak perlu disimpan karena manusia dengan pendengaran normal tidak akan bisa mendengar sinyal tersebut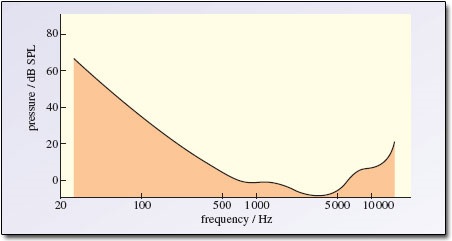
Batas pendengaran berdasarkan frekuensi. Semua sinyal di bawah garis hitam tidak bisa didengar oleh manusia dengan pendengaran normal Sumber:open.ac.uk - Masking
Masking merupakan fenomena saat suara dengan intensitas lebih kecil tidak akan terdengar jika ada suara dengan intensitas lebih besar ada di sekitarnya. Contoh nyatanya, di perpustakaan yang sunyi, bunyi langkah kaki orang berjalan di jarak 10 m dari posisi kita akan dengan mudah terdengar. Namun, di jalan raya yang bising, kita tidak bisa mendengar langkah kaki yang sama.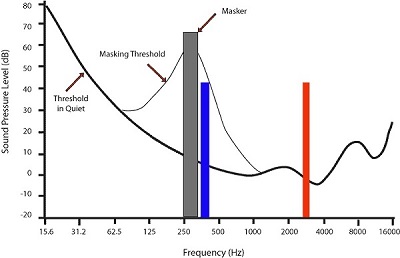
Ilustrasikan fenomena masking. Sumber gambar: madrondigital.com Perhatikan gambar ilustrasi fenomena masking. Pada kondisi sunyi, batas pendengaran manusia adalah garis hitam tebal (threshold in quiet). Jika ada suara yang keras, seperti kolom abu-abu, garis hitam tebal tadi akan berubah menjadi garis hitam tipis (masking threshold) yang mengikuti tingkat intensitas kolom abu-abu.Semua komponen sinyal suara di bawah garis hitam tipis yang baru tidak akan terdengar oleh manusia. Dalam kasus ini, suara yang ditampilkan dengan warna biru tidak akan bisa terdengar dan tidak perlu disimpan. Kolom yang berwarna merah adalah kolom suara yang tidak terpengaruh oleh kolom abu-abu, sehingga tetap harus disimpan.
Penggunaan karakteristik fisika dan matematika
Selain hasil riset kedokteran dan psikologi, MP3 memanfaatkan ilmu matematika dan fisika untuk mengurangi data yang perlu disimpan.
- Variasi sampling frekuensi
Untuk merepresentasikan frekuensi dari 20Hz sampai 20kHz kita menggunakan sampling frekuensi hingga di atas 40 kHz. Nyatanya, untuk sinyal-sinyal tertentu, penggunaan sampling frekuensi di atas 40 kHz ini tidak efisien. Contohnya, saat merekam percakapan di telepon. Percakapan manusia dalam kondisi normal hanya memiliki komponen frekuensi hingga 3400 Hz. Untuk sistem telepon, sampling frekuensi yang digunakan hanya sebesar 8 kHz, yang mendukung rekonstruksi hingga 4 kHz.MP3 memanfaatkan karakteristik tersebut untuk beberapa tipe sinyal suara, yaitu dengan menurunkan laju sampling frekuensi jika dideteksi sinyal suara hanya memiliki komponen frekuensi hingga batas tertentu saja. Dengan memvariasikan sampling frekuensi sesuai kebutuhan, data yang harus disimpan juga dapat dikurangi. - Joint stereo (kemiripan frekuensi telinga kiri dan kanan)
Pada sistem pendengaran manusia normal, sinyal akan didengar melalui kedua telinga kita. Pada kondisi nyata, suara yang masuk ke telinga kiri dan telinga kanan memiliki kemiripan. MP3 memanfaatkan karakteristik ini dengan merepresentasikan sinyal yang dikirim bukan dengan sinyal kanan dan sinyal kiri, tetapi dengan sinyal yang sama beserta pembedanya.Contoh sederhananya, sinyal kiri adalah [0.5 0.7] dan sinyal kanan [0.4 0.8]. Dengan joint stereo data tersebut akan diubah menjadi rata-rata dari kedua sinyal, yaitu [0.45 0.65] dan pembedanya, biasanya direpresentasikan dengan kiri dikurangi kanan, yaitu [0.1 -0.1]. Sinyal awal bisa didapatkan dengan cara rekonstruksi sinyal. - Huffman encoding
Huffman encoding bekerja dengan prinsip statistika, yaitu sinyal diurutkan dari yang paling sering keluar hingga yang paling jarang keluar. Setelah itu, sinyal yang paling sering keluar diganti (encode) dengan simbol yang paling pendek, dan seterusnya, sehingga angka yang paling jarang keluar mendapat simbol yang paling panjang.Contoh sederhananya, dengan bit depth 2 bit, ada 22 aternatif nilai, yaitu: 00, 01, 10, dan 11. Sistem pembagian tradisional akan membagi sinyal ini, menjadiNilai Simbol -0.75 00 -0.25 01 0.25 10 0.75 11 Misalnya kita mendapatkan sinyal yang nilainya [0.25 0.25 0.25 -0.75 0.75 0.75 -0.25 0.25], representasi digital dari sinyal ini adalah [10 10 10 00 11 11 01 01 ], dengan total panjang 16 karakter. Dengan Huffman coding sinyal pertama akan diurutkan berdasarkan jumlah kemunculannya.
Nilai Jumlah Kemunculan Simbol 0.25 4 1 0.75 2 01 -0.25 1 001 -0.75 1 000 Berdasarkan skema Huffmann, simbol sinyal pada contoh ini berubah menjadi [1 1 1 000 01 01 001 1 ] dengan total panjang 14 karakter. Huffman encoding sangat efisien untuk menyimpan sinyal yang kemunculannya sering berulang.
Pada aplikasi di dunia nyata, sinyal suara akan memiliki probabilitas tertentu. Probabilitas ini diakibatkan oleh karakteristik fisis dari sumber suara itu sendiri. Misalnya suara ombak di pantai akan memiliki hubungan probabilitas dengan siklus rotasi dan revolusi bumi.
Jadi, apa itu MP3?
MP3 adalah mekanisme mengompres data audio dengan memanfaatkan konsep karakteristik pendengaran manusia, ilmu fisika, serta matematika. Karena sistem kompresi MP3 menghilangkan sebagian besar sinyal yang tidak didengar oleh telinga manusia, sistem kompresi MP3 disebut juga sistem kompresi lossy.
Pada sistem kompresi MP3, seberapa besar data yang bisa dikurangi sangat bergantung kepada sinyal suara yang diproses. Sebagai rasio perbandingan, sinyal suara 3 menit yang menurut perhitungan sederhana menghasilkan data dengan ukuran sebesar 130 MB, maka dengan kompresi MP3 ukurannya bisa dikurangi menjadi sekitar 3-7 MB.
Ada juga tipe kompresi lain, misalnya FLAC, yang tidak menghilangkan detail sinyal suara yang dianggap tidak penting (loseless). Pada tipe kompresi ini, tidak ada pemrosesan data berdasarkan karakteristik pendengaran manusia, dan semua pemrosesan hanya memanfaatkan karakteristik matematika dari sinyal suara yang diproses.
Dengan demikian, efek dari pengurangan data berdasarkan karakteristik pendengaran dan karakteristik matematika bisa digambarkan dengan perbedaan antara ukuran data yang diproses dengan kompresi lossy seperti MP3, dan kompresi lossless seperti FLAC. Namun, perlu ditekankan sekali lagi, semua ini sangat bergantung pada sinyal yang diproses.
Bahan bacaan:
- http://hyperphysics.phy-astr.gsu.edu/hbase/sound/earsens.html
- http://aes.org/sections/pnw/ppt/jj/perceptual_coding.ppt
- http://cl.cam.ac.uk/teaching/0809/InfoTheory/HighLitedErrsNotes.pdf
Penulis:
Arif H. Wicaksono, mahasiswa S2 Teknik Elektro, Tohoku University, Jepang. Kontak: arifhw(at)zoho.com


